
Data Concepts for Agentic AI Process Automation & Workflows

The infin8 simple guide to Data Concepts for Agentic AI
Process Automation & Workflows
Let’s start with some definitions:
Ontology
- A shared definition of the core business concepts and how they relate.
- Gives AI clear concepts and relationships to reason about.
Entity
- A real-world object or concept that data represents.
- Helps AI distinguish persona, products, entity
Metadata
- Data that explains other data.
- Helps AI understand meaning e.g. Fund domicile, instrument data CUSIP / SEDOL / ISIN etc.,
Context
- The information that gives prompts & AI systems meaning in a specific situation.
- Helps AI produce relevant & accurate responses.
Intent
- The goal or purpose behind a user request, workflow or business action.
- Derived from language, context and behaviour.
Data modelling
- Designing how entities and their relationships are represented in data.
- Reduces ambiguity in how AI interprets data.
Data pipeline
- The flow of data from creation to consumption.
- Supplies AI with timely, relevant data.
Unstructured data
- Information that does not fit neatly into rows and columns, such as text, images or audio.
- Captures rich, real-world detail not found in structured data.
Semantic layer
- A business-friendly layer that defines consistent metrics.
- Ensures use of consistent definitions by users, decision makers & AI.
Observability
- The ability to see what data systems are doing, and detect issues early.
- Supports early detection of drift and unexpected behaviour.
Data governance
- The policies and controls that manage how data is used, accessed and protected.
- Helps to ensure data is trusted, secure and compliant.
Data lineage
- The trace of where data comes from, how it changes and where it is used.
- Provides more transparency and explainability for AI outputs.
Orchestration
- The coordination of when and how data pipelines run.
- Keeps inputs and jobs reliable and well-sequenced.
Vector database
- A database designed to search using similarity rather than exact matches.
- Enables richer retrieval and contextual understanding.
Grounding
- Connecting AI outputs to trusted data in real-world systems.
- Reduces errors and improves reliability.
Are vector databases still needed for Agentic AI if you already have RAG, Cache‑Augmented Generation (CAG), and Context‑Augmented Generation?
Short answer: Yes — in most real-world systems, vector databases remain essential.
But the reason why depends on what each technique actually solves.
-
Why Vector Databases Still Matter
Cross industry guidance for modern RAG frameworks, and agentic‑AI engineering deep dives, vector databases are described as a core enabling technology for retrieval‑based AI — not something replaced by caching or context expansion.
What the evidence says:
- Vector databases are described as foundational for RAG and agentic AI because they enable high‑quality semantic retrieval at speed and scale.
- RAG relies on retrieving semantically similar documents from a large corpus, which requires storing and querying embeddings efficiently.
- Google Vertex AI explicitly states vector databases play a crucial role in RAG because embeddings allow accurate, fast, semantically aware retrieval.
- Modern agentic systems typically perform multiple retrievals per reasoning step, requiring low-latency ANN search that only vector DBs can provide.
Conclusion:
Vector DBs solve the semantic memory and scalable retrieval problem.
CAG and caching do not replace that.
-
What Cache‑Augmented and Context‑Augmented Generation Actually Do
These methods improve performance, latency, or context coherence, but they don’t replace long‑term semantic storage.
Cache‑Augmented Generation (Caching)
- Stores recent model activations or queries, not a knowledge corpus.
- Great for repeated or similar queries.
- Not a substitute for searching millions of documents, contracts, files, or policies.
Context‑Augmented Generation (CAG)
- Expands useful context or improves how context is assembled.
- Works on the retrieved data — but still depends on retrieval quality.
- Does not solve the “where does the information come from?” problem.
-
“Do I still need a Vector DB if I have Agentic AI?”
Almost always: yes.
Agentic AI systems need:
- Long-term memory
– Vector DBs provide persistent, searchable memory across sessions.
– Caches don’t. - Semantic reasoning over large corpora (the standard plural used when referring to multiple bodies of text, documents, or datasets)
– Vector search enables similarity-based retrieval; classical DBs cannot do this at scale.
– CAG/caches assume the right info has already been retrieved. - Multi-step retrieval for multi-hop reasoning
– Agents frequently call tools to find new information, requiring vector search at each step. - High recall across millions of documents
– Only dedicated vector stores with ANN indexes (HNSW, PQ, DiskANN) can do this efficiently. Approximate Nearest Neighbour (ANN) is a method used in vector databases to find the closest (most semantically similar) vectors quickly, even when you have millions or billions of embeddings.
-
When Vector DBs Might Not Be Needed
There are a few specific scenarios:
Small knowledge bases
If your dataset is only a few thousand documents, in‑memory embedding search or local FAISS may be enough. FAISS is an open‑source library (by Meta/FAIR) for fast similarity search and clustering of dense vectors
Strong keyword-centric domains
If semantics matter less than metadata queries or structured fields, hybrid relational search may outperform vectors.
(Graph RAG is emerging because vector search can struggle with relational reasoning.)
Systems relying on pure in‑model memory
Some agentic patterns store working memory inside the agent or a cache — but this is short-term and not suitable for enterprise retrieval.
-
infin8 Practical Guidance on Vector Database in your AI platform
You probably still need a vector database if your AI system needs:
- retrieval over large corpora
- semantic search
- multi-step reasoning
- grounded, factual responses
- long-term agent memory
- scalable performance
You may get by without one if your system is:
- small
- temporary
- mostly repetitive queries
- structured-data–heavy
The infin8 Opinion

Agentic AI + RAG + caching methods work together, not as replacements. Each solves a different piece:
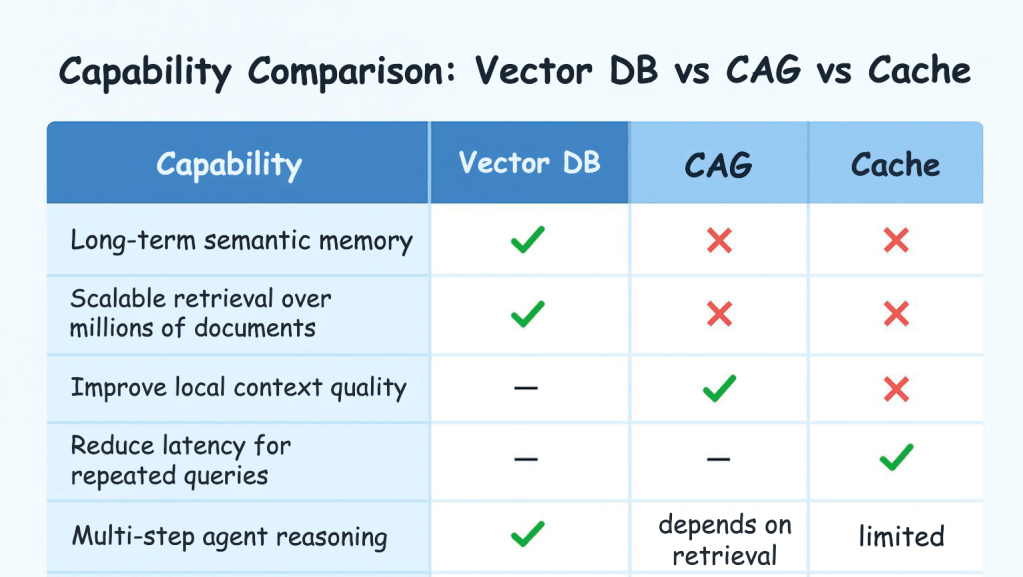
Vector DBs remain the backbone of retrieval.
Sources: servicesground.com, dev.to, dasroot.net, Vertex-AI, AI infin8.